"Design a web crawler" (like Googlebot) tests pipeline thinking, politeness, and deduplication at scale. The heart of the design is the URL frontier — the queue that decides what to crawl next, and how to do it without hammering any single website.
Here's the full walkthrough with a pipeline diagram, including robots.txt politeness and how to avoid crawler traps.
1. Clarify the requirements
Functional requirements
- Start from seed URLs and discover new pages by following links
- Download and store page content for indexing
- Respect robots.txt and per-host rate limits
- Avoid re-crawling the same content; re-crawl for freshness on a schedule
Non-functional requirements
- Scale to billions of pages
- Politeness — never overload a host
- Robustness against malformed pages and crawler traps
- Extensible to new content types
Back-of-the-envelope scale: Assume a target of 1B pages/month → ~400 pages/sec sustained. With average pages of ~100KB, that's ~100TB/month of raw content before deduplication.
2. API design
A crawler is an internal pipeline rather than a public API. Its core loop, conceptually:
loop:
url = frontier.next() # politeness-aware pick
if not allowed(url): continue # robots.txt + dedup check
html = fetch(url) # with per-host rate limit
links = parse(html) # extract URLs + text
store(url, content) # to content store
for link in links:
if not seen(link): frontier.add(link)3. High-level architecture
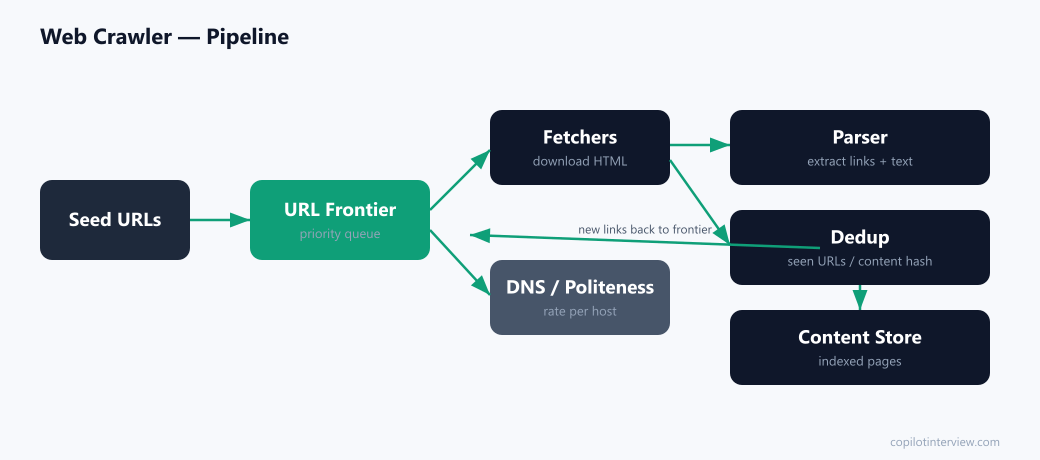
The URL frontier is the centerpiece: a set of priority queues that selects the next URL while enforcing politeness — never sending two requests to the same host too close together. It balances priority (important pages first) with per-host rate limits.
Pools of fetcher workers download pages (using a cached DNS resolver to avoid repeated lookups), the parser extracts links and text, and new links flow back into the frontier — a closed loop. A dedup stage drops URLs already seen and pages whose content hash matches something stored.
Politeness is enforced by honoring robots.txt (cached per host), applying any crawl-delay, and rate-limiting per domain. This is the detail that separates a real crawler design from a naive BFS.
4. Data model & storage
Seen-URL set: billions of URLs, checked on every discovered link. A bloom filter gives a compact, fast "probably seen" test, backed by an authoritative store for confirmation.
Content store: raw and parsed page content in object storage, keyed by URL hash, with a content hash for near-duplicate detection. Metadata (last-crawled, status, freshness) lives in a separate index.
5. Scaling and bottlenecks
- Distribute the frontier by host hash so each crawler node owns a set of domains — politeness stays local and there's no central bottleneck.
- Many fetcher workers running in parallel; I/O-bound, so concurrency is high.
- Bloom filter for dedup keeps the seen-set check fast and memory-efficient at billions of URLs.
- Re-crawl scheduling by page-change frequency so fresh pages are revisited more often than static ones.
Key trade-offs the interviewer probes
- Freshness vs coverage. Re-crawling known pages keeps the index fresh but spends budget you could use discovering new pages. Prioritize by change frequency and importance.
- Dedup accuracy. A bloom filter is compact but has false positives (it may skip a genuinely new URL); back it with an authoritative check for important pages.
- Crawler traps. Infinite calendar pages and session-ID URLs generate endless links. Defend with URL-depth limits, per-host page caps, and pattern detection.
Framework reminder: every system design answer follows the same arc — requirements → estimates → API → high-level design → data model → scale → trade-offs. Keep the system design cheat sheet in mind and narrate which stage you're in.
Design data pipelines with live AI support
CoPilot Interview surfaces a structured design skeleton — requirements, API, data model, and scaling — in about 4 seconds during real Zoom and Teams calls. Free for Windows and macOS, with a private desktop window.
Download freeFAQ
What is the URL frontier in a web crawler?
The frontier is the queue (really a set of priority queues) that decides which URL to crawl next while enforcing politeness - never hitting the same host too frequently. It balances page priority against per-host rate limits and is the centerpiece of the design.
How does a crawler avoid crawling the same page twice?
It maintains a 'seen URL' set, checked on every discovered link. At billions of URLs a bloom filter gives a compact, fast 'probably seen' test, backed by an authoritative store for confirmation. Content hashing additionally catches near-duplicate pages at different URLs.
How do you make a crawler polite?
Honor robots.txt (cached per host), respect any crawl-delay directive, and rate-limit requests per domain so you never overload a site. Distributing the frontier by host keeps politeness enforcement local to each crawler node.
What are crawler traps and how do you handle them?
Crawler traps are pages that generate effectively infinite URLs - endless calendars, session-ID links, or deep recursive paths. Defend with URL-depth limits, a per-host page cap, and pattern detection that spots and skips trap-like URL structures.
How do you scale a crawler to billions of pages?
Distribute the frontier by host hash so each node owns a set of domains, run many parallel fetcher workers (crawling is I/O-bound), use a bloom filter for fast dedup, and store content in object storage. Schedule re-crawls by how often each page changes.