"Design a notification system" tests asynchronous, reliable delivery across multiple channels — push, email, SMS, in-app. The architecture is a textbook queue-and-workers pipeline, and the interview depth comes from reliability: retries, de-duplication, and respecting user preferences.
Here's the full walkthrough with a diagram, including idempotency and how to scale through third-party provider limits.
1. Clarify the requirements
Functional requirements
- Send notifications over push, email, SMS, and in-app channels
- Apply templates and personalization
- Respect per-user preferences and opt-outs
- De-duplicate so a user isn't notified twice for the same event
Non-functional requirements
- Reliable — notifications shouldn't be silently dropped
- Scalable to millions of notifications/hour
- Decoupled from the services that trigger notifications
- Handle third-party provider rate limits and outages
Back-of-the-envelope scale: Assume 100M users and 10M notifications/hour at peak (e.g., a broadcast). The system must absorb spikes without overwhelming downstream providers — which is exactly what a queue is for.
2. API design
Internal services call a single notification API; the heavy lifting happens asynchronously behind a queue.
POST /api/notify
{
"userId": "...", "event": "order_shipped",
"channels": ["push", "email"],
"data": { "orderId": "...", "eta": "..." },
"idempotencyKey": "order_shipped:9912"
}
-> 202 Accepted (queued; delivery is async)3. High-level architecture
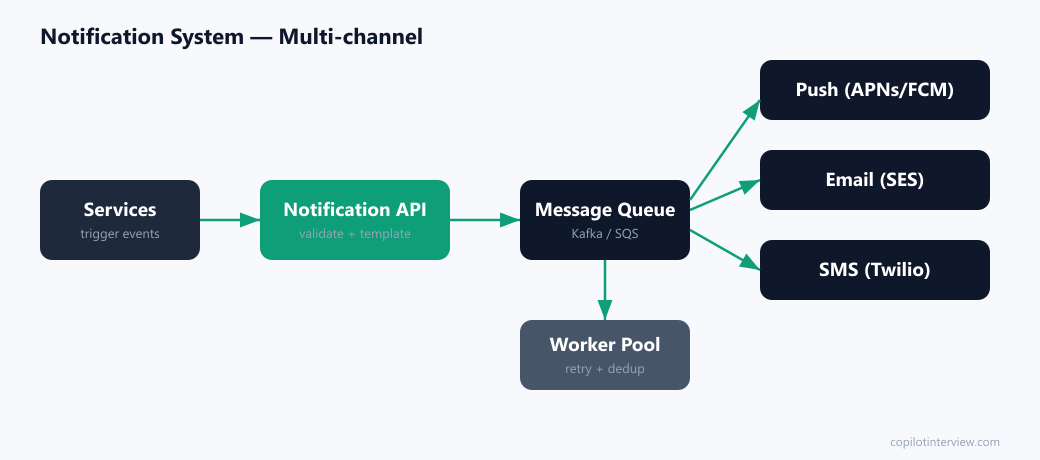
A thin notification API validates the request, applies the template, checks the user's preferences/opt-outs, and enqueues a job. It returns 202 Accepted immediately — callers never block on actual delivery.
A durable message queue (Kafka/SQS) decouples producers from delivery and absorbs spikes. A worker pool consumes jobs and dispatches to the right channel provider: APNs/FCM for push, an email service (SES) for email, Twilio for SMS.
Reliability is the meat: workers retry with exponential backoff on transient provider failures, route permanently-failed jobs to a dead-letter queue for inspection, and use the idempotency key to ensure a duplicate event never sends two notifications.
4. Data model & storage
User preferences: per-user, per-channel, per-category opt-in/opt-out settings, checked before every send so unsubscribes are honored immediately.
Notification log: a record of what was sent, to whom, on which channel, and the provider's delivery status — used for de-duplication, debugging, and analytics. The idempotency key is stored here to reject duplicates.
5. Scaling and bottlenecks
- Queue absorbs spikes so a 10M-notification broadcast drains at a controlled rate instead of melting downstream providers.
- Scale workers horizontally and use separate queues/priorities per channel so a slow SMS provider doesn't block push delivery.
- Respect provider rate limits with per-provider throttling; batch where the provider supports it.
- Idempotency + dedup log guarantees at-least-once delivery without double-notifying.
Key trade-offs the interviewer probes
- At-least-once + dedup vs exactly-once. Exactly-once delivery is impractical; instead deliver at-least-once and de-duplicate with an idempotency key. This is the central reliability decision.
- Priority queues. A security OTP must beat a marketing blast — separate priorities or queues prevent low-priority floods from delaying urgent notifications.
- Sync vs async. Returning 202 and delivering asynchronously keeps callers fast and lets you retry, at the cost of not knowing delivery status at request time (surface it via the log/webhooks).
Framework reminder: every system design answer follows the same arc — requirements → estimates → API → high-level design → data model → scale → trade-offs. Keep the system design cheat sheet in mind and narrate which stage you're in.
Design reliable pipelines with live AI support
CoPilot Interview surfaces a structured design skeleton — requirements, API, data model, and scaling — in about 4 seconds during real Zoom and Teams calls. Free for Windows and macOS, with a private desktop window.
Download freeFAQ
How do you make a notification system reliable?
Persist and enqueue every request on a durable queue, have workers retry with exponential backoff on transient failures, route permanently-failed jobs to a dead-letter queue, and deduplicate with an idempotency key. The goal is at-least-once delivery without double-notifying.
How do you prevent duplicate notifications?
Attach an idempotency key to each event (for example 'order_shipped:9912') and store it in a notification log. Before sending, check whether that key was already processed; if so, skip it. This makes at-least-once delivery safe even when a message is retried.
Why use a message queue for notifications?
A queue decouples the services that trigger notifications from the delivery workers and absorbs spikes - a 10-million-notification broadcast drains at a controlled rate instead of overwhelming downstream providers. It also enables retries and lets callers return immediately.
How do you handle user preferences and opt-outs?
Store per-user, per-channel, per-category preferences and check them in the notification API before enqueuing or sending. Honoring opt-outs immediately (and at send time) keeps the system compliant and avoids sending unwanted messages.
How do you handle different channels like push, email, and SMS?
A worker pool dispatches each job to the appropriate provider - APNs/FCM for push, an email service like SES, Twilio for SMS - often with separate queues or priorities per channel so a slow provider on one channel doesn't block the others.