"Design a URL shortener" (TinyURL, Bitly) is the canonical warm-up system design question. It looks simple, but it exercises every core skill the interviewer wants to see: estimating scale, choosing an encoding scheme, designing for a read-heavy workload, and reasoning about caching and trade-offs.
Here's the complete walkthrough with an architecture diagram, following the standard requirements → API → design → data → scale arc.
1. Clarify the requirements
Functional requirements
- Given a long URL, return a short URL
- Given a short URL, redirect to the original
- Optional: custom alias, expiration, and click analytics
Non-functional requirements
- High availability — redirects must not fail
- Low latency redirects (under ~100ms)
- Short codes should not be easily guessable
- Read-heavy: roughly 100:1 reads to writes
Back-of-the-envelope scale: Assume ~100M new URLs/day → ~1,160 writes/sec and ~100K reads/sec at peak. Over 5 years that's ~180B URLs, so plan for a key space larger than that.
2. API design
Two endpoints carry the whole service. Keep the create path authenticated/rate-limited and the redirect path as fast as possible.
POST /api/shorten
body: { "url": "https://example.com/very/long/path", "alias?": "promo" }
-> 200 { "shortUrl": "https://sho.rt/aZ8kQ1x" }
GET /{code}
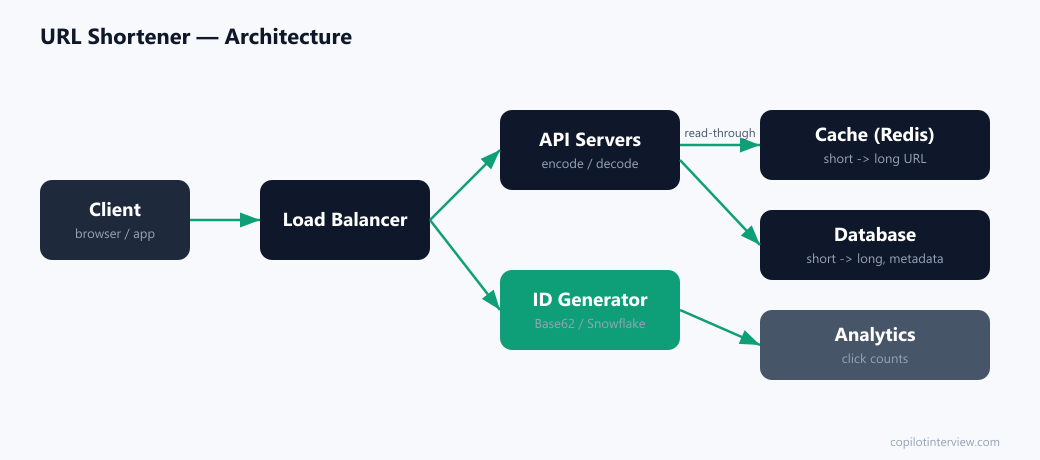
-> 301 (or 302) redirect to the original long URL3. High-level architecture
A load balancer spreads traffic across stateless API servers. The write path calls an ID generator to produce a unique number, which is encoded to a short code; the read path looks the code up and redirects.
Because the workload is overwhelmingly reads, a cache (Redis) sits in front of the database holding the hottest code → longUrl mappings. Most redirects are served straight from cache in single-digit milliseconds.
Encoding: the cleanest approach is to take a unique 64-bit ID (from a counter range service or a Snowflake-style generator) and Base62-encode it (a-z, A-Z, 0-9). Seven Base62 characters give 62⁷ ≈ 3.5 trillion codes. The alternative — hashing the URL (MD5) and taking a prefix — is simpler but requires collision handling.
4. Data model & storage
The core store is a simple key-value mapping: code (primary key) → longUrl, plus createdAt, userId, and optional expiresAt. This is a perfect fit for a horizontally-scalable NoSQL store (DynamoDB, Cassandra) partitioned by code.
Analytics (click counts, referrers) are written asynchronously to a separate store or stream so they never slow the redirect path.
5. Scaling and bottlenecks
- Cache the hot set. A small fraction of URLs get most traffic; a Redis cache with LRU eviction absorbs the read load.
- Partition by code. The key-value store shards cleanly on the short code, so it scales horizontally with no hotspots.
- Use a CDN/edge for redirects if global latency matters.
- Pre-generate IDs in ranges so each API server hands out codes without contending on a single counter.
Key trade-offs the interviewer probes
- 301 vs 302 redirect. 301 (permanent) is cacheable by browsers — fastest, but you lose per-click analytics because repeat visits never hit your server. 302 (temporary) routes every click through you, preserving analytics at the cost of load. Most shorteners use 302 for exactly this reason.
- Counter vs hash for codes. A counter gives short, collision-free codes but they're sequential and guessable; hashing is random but needs collision checks. A counter plus Base62 is the common answer.
- Custom aliases require a uniqueness check and a separate lookup path — mention the added write-path complexity.
Framework reminder: every system design answer follows the same arc — requirements → estimates → API → high-level design → data model → scale → trade-offs. Keep the system design cheat sheet in mind and narrate which stage you're in.
Structure any design answer with live AI support
CoPilot Interview surfaces a structured design skeleton — requirements, API, data model, and scaling — in about 4 seconds during real Zoom and Teams calls. Free for Windows and macOS, with a private desktop window.
Download freeFAQ
How do you generate the short code?
Take a unique 64-bit ID from a counter-range service or a Snowflake-style generator and Base62-encode it (a-z, A-Z, 0-9). Seven characters yield about 3.5 trillion codes. Alternatively, hash the URL and take a prefix, but then you must handle collisions.
Should a URL shortener use a 301 or 302 redirect?
302 (temporary) is usually preferred because every click routes through your server, preserving click analytics. 301 (permanent) is cacheable by the browser so it's faster and lighter, but you lose analytics on repeat visits. It's the classic trade-off the interviewer wants you to surface.
How do you handle the read-heavy workload?
Put a cache (Redis) in front of the database holding the hottest code-to-URL mappings, partition the key-value store by code, and optionally serve redirects from a CDN/edge. Reads outnumber writes ~100:1, so caching is the main lever.
What database fits a URL shortener?
A horizontally-scalable key-value/NoSQL store like DynamoDB or Cassandra, partitioned by the short code. The access pattern is a simple primary-key lookup, so a relational database isn't necessary at scale.
How do you support custom aliases?
Accept an optional alias on the create call, check it isn't already taken (a uniqueness constraint or conditional write), and store it like any other code. The added cost is the uniqueness check on the write path.