"Design a news feed" (Twitter timeline, Instagram feed, Facebook feed) is a flagship system design question because it forces a real architectural decision — how to assemble each user's timeline — with no free lunch. The whole interview hinges on the fan-out choice.
Here's the full walkthrough with a diagram, including the famous celebrity problem and where ML ranking belongs.
1. Clarify the requirements
Functional requirements
- Users can publish a post
- Users can follow other users
- A user's home timeline shows recent posts from people they follow, ranked
- A user timeline shows that user's own posts
Non-functional requirements
- Read-heavy — timelines are viewed far more than posts are written
- Low timeline latency (feed should load fast)
- Eventually consistent is acceptable (a post can take seconds to appear)
- Handle highly skewed graphs (accounts with tens of millions of followers)
Back-of-the-envelope scale: Assume 500M daily users, ~50M posts/day, average 200 follows. Timeline reads dwarf writes, so optimizing the read path is the priority — until celebrities break the naive approach.
2. API design
Three operations cover it. The home-timeline read is the hot path and must be cheap.
POST /api/posts { "text": "...", "media?": [...] }
POST /api/follow { "targetUserId": "..." }
GET /api/feed?cursor=... -> ranked list of posts (paginated)3. High-level architecture
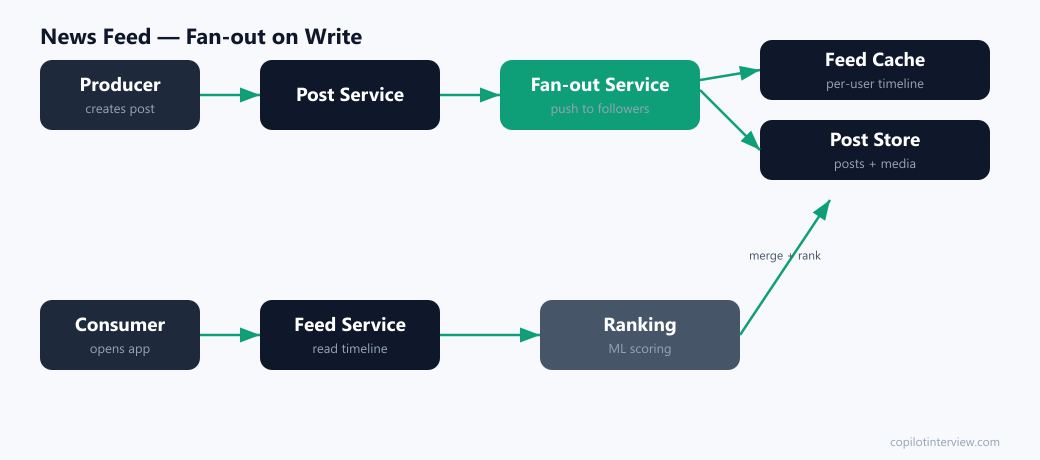
Fan-out on write (push): when a user posts, the fan-out service immediately writes the post ID into each follower's feed cache (a Redis list per user). Reads are then trivially fast — just read your precomputed list. The cost: a celebrity with 50M followers triggers 50M writes per post.
Fan-out on read (pull): store posts once; at read time, the feed service gathers recent posts from everyone you follow and merges them. Writes are cheap, but reads are expensive and slow for users who follow many accounts.
The production answer is a hybrid: push for normal users (fast reads), and pull for posts from celebrity accounts (avoid the write storm), merging the two at read time. Naming this hybrid and the celebrity problem is the single highest-signal moment in the interview.
Either way, a ranking stage scores the merged candidate posts by recency, author affinity, and predicted engagement before returning the page.
4. Data model & storage
Post store: posts keyed by post ID with author, text, media references, and timestamp — partitioned by post ID. Media lives in object storage behind a CDN.
Social graph: follower/followee edges, stored to support fast "who follows X" and "who does X follow" lookups.
Feed cache: a per-user list of recent post IDs in Redis — the precomputed timeline for push users. Bounded in length (e.g., latest few hundred) so it stays small.
5. Scaling and bottlenecks
- Cache timelines in Redis; the feed read becomes a list fetch plus hydration of post bodies.
- Shard by user ID for feed caches and by post ID for the post store.
- Asynchronous fan-out via a message queue so posting returns immediately and delivery happens in the background.
- CDN for media so images/video never touch your app servers on the read path.
Key trade-offs the interviewer probes
- Push vs pull vs hybrid. Push = fast reads, expensive writes (celebrity storms). Pull = cheap writes, slow reads. Hybrid = best of both with added complexity. Always land on the hybrid and explain why.
- The celebrity problem. Fan-out on write doesn't scale for accounts with millions of followers; pulling their posts at read time fixes it. This is the detail interviewers wait for.
- Consistency. Feeds are eventually consistent — a brief delay before a post appears is acceptable and lets you do fan-out asynchronously.
Framework reminder: every system design answer follows the same arc — requirements → estimates → API → high-level design → data model → scale → trade-offs. Keep the system design cheat sheet in mind and narrate which stage you're in.
Land the fan-out trade-off with live AI support
CoPilot Interview surfaces a structured design skeleton — requirements, API, data model, and scaling — in about 4 seconds during real Zoom and Teams calls. Free for Windows and macOS, with a private desktop window.
Download freeFAQ
What's the difference between fan-out on write and fan-out on read?
Fan-out on write (push) precomputes each follower's timeline when a post is created, making reads fast but writes expensive. Fan-out on read (pull) stores posts once and assembles the timeline at read time, making writes cheap but reads slow. Production systems use a hybrid.
What is the celebrity problem in a news feed?
With fan-out on write, a post from an account with tens of millions of followers triggers that many timeline writes - a write storm. The fix is to pull celebrity posts at read time instead of pushing them, while still pushing normal users' posts. Naming this is high-signal in the interview.
How do you rank a news feed?
After gathering candidate posts (via push, pull, or both), a ranking stage scores them by recency, affinity to the author, and predicted engagement using an ML model, then returns the top page. Chronological is the simple baseline; ranking is the upgrade.
How do you store the timeline?
As a per-user list of recent post IDs in a cache like Redis (the precomputed feed for push users), bounded to the latest few hundred entries. Post bodies and media live in a separate post store and object storage/CDN, hydrated at read time.
Is a news feed strongly consistent?
No - eventual consistency is the norm and is acceptable. A new post taking a few seconds to appear in followers' feeds lets you do fan-out asynchronously through a queue, which is essential for scale.